Appearance
LangGraph API
API 之 Graph(图)

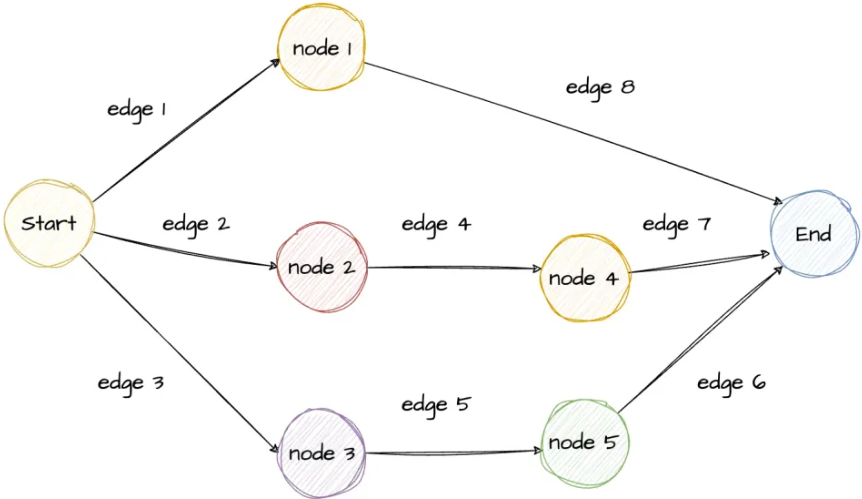
图的构建流程:
- 初始化一个StateGraph实例。
- 添加节点。
- 定义边,将所有的节点连接起来。
- 设置特殊节点,入口和出口(可选)。
- 编译图。
- 执行工作流。
python
from typing import TypedDict
from langgraph.constants import START, END
from langgraph.graph import StateGraph
# 定义状态
class GraphState(TypedDict):
process_data: dict
def input_node(state: GraphState) -> GraphState:
print(
f"input_node节点执行state.get('process_data')方法结果: {state.get('process_data')}"
)
return {"process_data": {"input": "input_value"}}
def process_node(state: dict) -> dict:
print(
f"process_node节点执行state.get('process_data')方法结果: {state.get('process_data')}"
)
return {"process_data": {"process": "process_value9527"}}
def output_node(state: GraphState) -> GraphState:
print(
f"output_node节点执行state.get('process_data')方法结果: {state.get('process_data')}"
)
return {"process_data": state.get("process_data")}
# 创建一个状态图StateGraph并指定状态
graph = StateGraph(GraphState)
# 添加input、process、output节点
graph.add_node("input", input_node)
graph.add_node("process", process_node)
graph.add_node("output", output_node)
# 添加固定边,执行顺序:start -> input -> process -> output -> end
graph.add_edge(START, "input")
graph.add_edge("input", "process")
graph.add_edge("process", "output")
graph.add_edge("output", END)
# 编译图,保证生成的图是正确的,如果添加了边,没添加节点,会报错
app = graph.compile()
# 执行
result = app.invoke({"process_data": {"name": "测试数据", "value": 123456}})
print(f"最后的结果是:{result}")
# 打印图的ascii可视化结构
print(app.get_graph().print_ascii())
print("=================================")
print()
# 打印图的可视化结构,生成更加美观的Mermaid 代码,通过processon 编辑器查看
print(app.get_graph().draw_mermaid())API 之 State(状态)
在LangGraph中,State是一个贯穿整个工作流执行过程中的共享数据的结构,代表当前快照,

它存储了从工作流开始到结束的所有必要的信息(历史对话、检索到的文档、工具执行结果等),在各个节点中共享,且每个节点都可以修改。
状态包含两部分:
- 图的模式(schema)
- “规约函数”(reducer functions);后者指明如何把更新应用到状态上。
State组成
定义图时,首先要做的是定义图的State。State由图的schema以及reducer函数组成。
如何定义一个State
python
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
class BasicState(TypedDict):
"""基本的 State定义"""
user_input: str
response: str
count: int
process_data: dict
# 创建状态图,并指定状态结构
basicState = StateGraph(BasicState)
# 添加起始到结束的边(无中间节点)
basicState.add_edge(START, END)
# 编译生成计算图
app = basicState.compile()
# invoke()方法只接收状态字典作为核心参数
initial_state = {
"user_input": "a",
"response": "resp",
"count": 25,
"process_data": {"k1": "v1"}, # process_data本身是dict类型,需嵌套
}
# invoke() 仅接收 1 个核心位置参数(状态字典),可选 1 个配置参数,切勿传入多个独立参数。
result = app.invoke(initial_state)
# 打印结果验证
print("执行结果:", result)Schema

构成三要素:

state_schema:图的完整内部状态,包含了所有节点可能读写的字段,必须指定,不能为空
特点:是图的"全局状态空间";所有节点都可以访问和写入这个 schema 中的任何字段。
input_schema:定义图接受什么输入,是 state_schema 的子集
特点:可选参数,如果不指定,默认等于 state_schema;限制图的输入接口,只能传入这些字段
output_schema:定义图返回什么输出,是 state_schema 的子集
特点:可选参数,如果不指定,默认等于 state_schema;限制图的输出接口,只返回这些字段
State可以是TypedDict类型,也可以是pydantic中的BaseModel类型
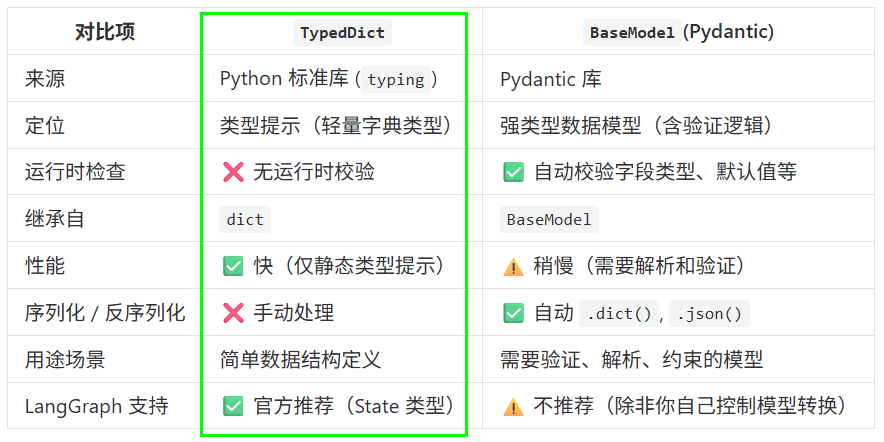
一句话选型
- 想要 轻量、无运行时开销、习惯字典写法 → 用 TypedDict
- 想要 自动校验、默认值、嵌套结构、字段描述 → 用 pydantic.BaseModel
- 两种写法在 LangGraph 里都能一键编译,只需按上例规则声明字段即可
python
"""
LangGraph 图输入输出模式和私有状态传递演示
该演示展示了:
1. 如何定义图的输入和输出模式
"""
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
# 定义输入状态模式
class InputState(TypedDict):
question: str
# 定义输出状态模式
class OutputState(TypedDict):
answer: str
# 定义整体状态模式,结合输入和输出
class OverallState(InputState, OutputState):
pass
# 定义处理节点
def answer_node(state: InputState):
"""
处理输入并生成答案的节点
Args:
state: 输入状态
Returns:
dict: 包含答案的字典
"""
print(f"执行 answer_node 节点:")
print(f" 输入: {state}")
# 示例答案
answer = "再见" if "bye" in state["question"].lower() else "你好"
result = {"answer": answer, "question": state["question"]}
print(f" 输出: {result}")
return result
def demo_input_output_schema():
"""演示输入输出模式"""
print("=== 演示输入输出模式 ===")
# 使用指定的输入和输出模式构建图
builder = StateGraph(
OverallState, input_schema=InputState, output_schema=OutputState
)
builder.add_edge(START, "answer_node") # 定义起始边
builder.add_node("answer_node", answer_node) # 添加答案节点
builder.add_edge("answer_node", END) # 定义结束边
graph = builder.compile() # 编译图
# 使用输入调用图并打印结果
result = graph.invoke({"question": "你好"})
print(f"图调用结果: {result}")
# 打印图的ascii可视化结构
print(graph.get_graph().print_ascii())
print()
def main():
"""主函数"""
print("=== LangGraph 图输入输出模式===\n")
# 演示输入输出模式
demo_input_output_schema()
print("=== 演示完成 ===")
if __name__ == "__main__":
main()Reducers
规约函数:规约函数决定了节点产生的更新如何作用到 State。State 中的每个字段都拥有自己的独立规约函数。 如果未显式指定,则默认所有对该字段的更新都会直接覆盖旧值。规约函数有多种类型,首先是默认类型“字段级合并策略”,它让节点只需吐出“增量”,框架负责按规则把增量焊进全局 State。
状态合并策略(Reducers)
LangGraph工作流中,State作为贯穿整个节点之间共享数据的结构,每一个节点都可以读取当前State的数据,并且可以更新。Reducer是定义多个节点之间State如何更新的(覆盖、合并、添加等)
Reducer函数在LangGraph中的作用:
- 控制状态更新方式:决定新值如何与现有值合并。
- 处理并行更新:当多个节点同时更新同一字段时,确保数据一致性。
- 提供灵活性:支持不同的合并策略,如覆盖、追加、相加等。
- 增强表达力:允许开发者根据业务需求自定义合并逻辑。
通过合理使用Reducer函数,可以构建更强大和灵活的状态管理机制,特别是在处理复杂工作流和并行执行场景时。
Reducer常用函数有以下几种:
- default:未指定Reducer时使用覆盖更新
- add_messages:用于消息列表追加
- operator.add:将元素追加到现有元素中,支持列表、字符串、数值类型的追加
- operator.mul:用于数值相乘
- 自定义Reducer:支持用户自定义合并逻辑
default
python
"""
如果未明确指定reducer函数,则默认对该键的更新是覆盖行为。
LangGraph Reducer函数演示 - 默认Reducer(覆盖更新)
直接覆盖:
如果没有为状态字段指定 Reducer,默认会覆盖更新。
也就是说,后执行的节点返回的值会直接覆盖先执行节点的值,
即下一个节点的State数据是上一个节点的返回。
"""
from typing import List
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
# 1. 默认Reducer(覆盖更新)
# 未指定合并策略,默认覆盖,上一个节点的返回是下一个节点的值
class DefaultReducerState(TypedDict):
foo: int
bar: List[str]
def node_default_1(state: DefaultReducerState) -> dict:
print(state["foo"])
print(state["bar"])
return {"foo": 22}
def node_default_2(state: DefaultReducerState) -> dict:
print()
print(state["foo"])
print(state["bar"])
return {"bar": ["bye1", "bye2", "bye3"]}
def main():
print("1. 默认Reducer(覆盖更新)演示:\n")
builder = StateGraph(DefaultReducerState)
builder.add_node("node1", node_default_1)
builder.add_node("node2", node_default_2)
builder.add_edge(START, "node1")
builder.add_edge("node1", "node2")
builder.add_edge("node2", END)
graph = builder.compile()
result = graph.invoke(input={"foo": 1, "bar": ["hi"]})
# print(f"初始状态: {{'foo': 1, 'bar': ['hi']}}")
print(f"执行结果: {result}\n")
if __name__ == "__main__":
main()
# 1. 默认Reducer(覆盖更新)演示:
# 1
# ['hi']
# 22
# ['hi']
# 执行结果: {'foo': 22, 'bar': ['bye1', 'bye2', 'bye3']}add_message
python
"""
LangGraph Reducer函数演示 - add_messages Reducer(消息列表专用)
"""
from typing import Annotated, List
from langchain_core.messages import HumanMessage, AIMessage
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 2. add_messages Reducer(消息列表专用)
class AddMessagesState(TypedDict):
"""
引入的 Annotated 类型,它允许给类型添加额外的元数据。
messages: Annotated[List, add_messages]
表示:
- messages 我的状态里只有一个字段叫 messages,类型是是 List列表类型,
- add_messages 这里的 add_messages 是一个函数,用于修改 messages 列表
每当节点返回对 messages 的“局部更新”时,
请用 add_messages 规约器把它合并到旧列表上(追加,而不是覆盖)
总结:
节点永远只 return 增量字典,不用手动把旧列表读出来再拼接。
add_messages 在后台帮你完成“追加”动作;如果换成默认 reducer,旧消息会被整份替换掉
"""
messages: Annotated[List, add_messages]
def chat_node_1(state: AddMessagesState) -> dict:
return {"messages": [("assistant", "Hello from node 1")]}
def chat_node_2(state: AddMessagesState) -> dict:
return {"messages": [("assistant", "Hello from node 2")]}
def run_demo():
print("2. add_messages Reducer(消息列表专用)演示:")
builder = StateGraph(AddMessagesState)
builder.add_node("chat1", chat_node_1)
builder.add_node("chat2", chat_node_2)
builder.add_edge(START, "chat1")
builder.add_edge(START, "chat2") # 并行执行
builder.add_edge("chat1", END)
builder.add_edge("chat2", END)
graph = builder.compile()
result = graph.invoke({"messages": [("user", "Hi there!")]})
print("初始状态: {{'messages': [('user', 'Hi there!')]}}")
print(f"执行结果: {result}\n")
print("*" * 60)
# 打印图的ascii可视化结构
print(graph.get_graph().print_ascii())
if __name__ == "__main__":
run_demo()
# 2. add_messages Reducer(消息列表专用)演示:
# 初始状态: {{'messages': [('user', 'Hi there!')]}}
# 执行结果: {
# 'messages': [
# HumanMessage(content='Hi there!', additional_kwargs={}, response_metadata={}, id='f029a089-9898-4b99-8882-1a01aac04cfc'),
# AIMessage(content='Hello from node 1', additional_kwargs={}, response_metadata={}, id='abc8bef1-ca86-4b5b-912b-e00cc4b60cff', tool_calls=[], invalid_tool_calls=[]),
# AIMessage(content='Hello from node 2', additional_kwargs={}, response_metadata={}, id='c9c12df7-bc15-4332-b5b6-15a248a9b524', tool_calls=[], invalid_tool_calls=[])
# ]
# }operator.add
python
"""
LangGraph Reducer函数演示 - operator.add Reducer(列表追加)
"""
import operator
from typing import Annotated, List
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
# 3. operator.add Reducer(列表追加)
class ListAddState(TypedDict):
# data: Annotated[List[int], None] #默认覆盖
data: Annotated[List[int], operator.add] # (列表追加)
def producer_1(state: ListAddState) -> dict:
return {"data": [1, 2]}
def producer_2(state: ListAddState) -> dict:
return {"data": [3, 4]}
def run_demo():
builder = StateGraph(ListAddState)
# 注册节点
builder.add_node("producer1", producer_1)
builder.add_node("producer2", producer_2)
# 顺序执行边
builder.add_edge(START, "producer1")
builder.add_edge("producer1", "producer2")
builder.add_edge("producer2", END)
graph = builder.compile()
result = graph.invoke({"data": [0]})
print("初始状态: {{'data': [0]}}")
print(f"执行结果: {result}\n")
if __name__ == "__main__":
run_demo()
# 初始状态: {{'data': [0]}}
# 执行结果: {'data': [0, 1, 2, 3, 4]}字符串连接 Reducer:
python
"""
LangGraph Reducer函数演示 - 字符串连接Reducer
"""
import operator
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
# 6. 字符串连接Reducer
class StringConcatState(TypedDict):
text: Annotated[str, operator.add]
def add_text_1(state: StringConcatState) -> dict:
return {"text": "Hello "}
def add_text_2(state: StringConcatState) -> dict:
return {"text": "World!"}
def run_demo():
print("3.2 字符串连接Reducer演示:")
builder = StateGraph(StringConcatState)
builder.add_node("add_text_1", add_text_1)
builder.add_node("add_text_2", add_text_2)
builder.add_edge(START, "add_text_1")
builder.add_edge(START, "add_text_2") # 并行执行
builder.add_edge("add_text_1", END)
builder.add_edge("add_text_2", END)
graph = builder.compile()
result = graph.invoke({"text": "Say: "})
print("初始状态: {{'text': 'Say: '}}")
print(f"执行结果: {result}\n")
if __name__ == "__main__":
run_demo()
# 3.2 字符串连接Reducer演示:
# 初始状态: {'text': 'Say: '}
# 执行结果: {'text': 'Say: Hello World!'}数值累加Reducer:
python
"""
LangGraph Reducer函数演示 - 数值累加Reducer
"""
import operator
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
# 7. 数值累加Reducer
class NumberAddState(TypedDict):
count: Annotated[int, operator.add]
def increment_1(state: NumberAddState) -> dict:
return {"count": 5}
def increment_2(state: NumberAddState) -> dict:
return {"count": 3}
def run_demo():
print("3.3 数值累加Reducer演示:")
builder = StateGraph(NumberAddState)
builder.add_node("increment_1", increment_1)
builder.add_node("increment_2", increment_2)
# 顺序执行边
builder.add_edge(START, "increment_1")
builder.add_edge("increment_1", "increment_2")
builder.add_edge("increment_2", END)
graph = builder.compile()
result = graph.invoke({"count": 10})
print(f"初始状态: {{'count': 10}}")
print(f"执行结果: {result}\n")
if __name__ == "__main__":
run_demo()
# 3.3 数值累加Reducer演示:
# 初始状态: {'count': 10}
# 执行结果: {'count': 18}operator.mul
python
"""
LangGraph Reducer函数演示 - operator.mul Reducer(数值相乘)
"""
import operator
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
# 4. operator.mul Reducer(数值相乘)
class MultiplyState(TypedDict):
factor: Annotated[float, operator.mul]
def multiplier(state: MultiplyState) -> dict:
return {"factor": 2.0}
def run_demo():
"""
这不是bug,是设计决策:LangGraph选择用类型默认值初始化状态字段
对于不同操作,需要不同处理:
加法:恒等元是0.0,所以operator.add可以直接用
乘法:恒等元是1.0,需要特殊处理初始的0.0
自定义reducer是标准做法:复杂的业务逻辑都应该使用自定义reducer
这是LangGraph使用中的一个常见陷阱!建议在使用乘法、除法等非加法操作时,总是使用自定义reducer来处理初始值问题
在执行初始阶段(我们定义的第一个node前),会默认调用一次reducer(后面自定义reducer案例中进行了打印验证),
用默认值与invoke传递的值进行计算:
此案例中,invoke中传递了一个默认值5.0,由于会默认调用一次reducer,
执行的计算是: 0.0(float默认值) * 5.0(invoke传递的初始值) = 0.0
导致后续乘法结果一直都是0
初始默认值: factor = 0.0
invoke传入: factor = 5.0
reducer计算: 0.0 * 5.0 = 0.0
然后才执行你的multiplier节点...
operator.mul作为 LangGraph 归约器的执行逻辑是:
最终值 = 初始值 * 增量值1 * 增量值2 * ...
归约器会迭代节点返回的增量值并依次相乘,若直接返回单个数值(非可迭代),会被判定为「无增量」,最终按初始值 * 空处理,而乘法中「空累积」的默认结果是乘法单位元 0.0。
解决方案: 使用自定义reducer
"""
print("4. operator.mul Reducer(数值相乘)演示:")
builder = StateGraph(MultiplyState)
builder.add_node("multiplier", multiplier)
builder.add_edge(START, "multiplier")
builder.add_edge("multiplier", END)
graph = builder.compile()
result = graph.invoke({"factor": 5.0})
print(f"初始状态: {{'factor': 5.0}}")
print(f"执行结果: {result}\n")
if __name__ == "__main__":
run_demo()
# 4. operator.mul Reducer(数值相乘)演示:
# 初始状态: {'factor': 5.0}
# 执行结果: {'factor': 0.0}自定义Reducer
python
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
def MyOperatorMul(current: float, update: float) -> float:
"""自定义乘法reducer,处理初始值为1.0"""
# 如果是第一次调用,current会是默认值0.0
if current == 0.0:
# 对于乘法,恒等元应该是1.0或者 return 1.0 * update
print(f"current:{current}")
print(f"update:{update}")
return 1.0 * update
return current * update
class MultiplyState(TypedDict):
factor: Annotated[float, MyOperatorMul]
def multiplier(state: MultiplyState) -> dict:
return {"factor": 2.0}
def run_demo():
print("使用自定义reducer解决乘法问题:")
builder = StateGraph(MultiplyState)
builder.add_node("multiplier", multiplier)
builder.add_edge(START, "multiplier")
builder.add_edge("multiplier", END)
graph = builder.compile()
result = graph.invoke({"factor": 5.0})
print("初始状态: {{'factor': 5.0}}")
print(f"执行结果: {result}") # 应该是 {'factor': 10.0}
print("解释: 5.0 * 2.0 = 10.0\n")
if __name__ == "__main__":
run_demo()
# 使用自定义reducer解决乘法问题:
# current:0.0
# update:5.0
# 初始状态: {{'factor': 5.0}}
# 执行结果: {'factor': 10.0}
# 解释: 5.0 * 2.0 = 10.0聊天机器人小案例
python
from typing import Annotated, List
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
import operator
class ChatState(TypedDict):
messages: Annotated[list, add_messages] # 消息历史
tags: Annotated[List[str], operator.add] # 标签列表
score: Annotated[float, operator.add] # 累计分数
def process_user_message(state: ChatState) -> dict:
user_message = state["messages"][-1] # 获取最新消息
return {
"messages": [("assistant", f"Echo: {user_message.content}")],
"tags": ["processed"],
"score": 1.0,
}
def add_sentiment_tag(state: ChatState) -> dict:
return {"tags": ["positive"], "score": 0.5}
# 构建图
builder = StateGraph(ChatState)
builder.add_node("process", process_user_message)
builder.add_node("sentiment", add_sentiment_tag)
builder.add_edge(START, "process")
builder.add_edge(START, "sentiment")
builder.add_edge("process", END)
builder.add_edge("sentiment", END)
graph = builder.compile()
# 使用示例 -使用正确的消息格式
result = graph.invoke(
{
"messages": [{"role": "user", "content": "Hello, how are you?"}],
"tags": ["greeting"],
"score": 0.0,
}
)
print(result)
# {
# "messages": [
# HumanMessage(
# content="Hello, how are you?",
# additional_kwargs={},
# response_metadata={},
# id="259efc74-5e90-4c01-a703-700e118b922e",
# ),
# AIMessage(
# content="Echo: Hello, how are you?",
# additional_kwargs={},
# response_metadata={},
# id="662e4e7f-d8a2-42c0-879e-c88d62cfc47d",
# tool_calls=[],
# invalid_tool_calls=[],
# ),
# ],
# "tags": ["greeting", "processed", "positive"],
# "score": 1.5,
# }API 之 Node (节点)
在LangGraph中,节点(Node)就是是Python函数(可以是同步的,也可以是异步的),它们接受以下参数:
- state:图的状态
- config:一个RunnableConfig对象,包含诸如thread_id之类的配置信息以及诸如tags之类的跟踪信息
- runtime:一个Runtime对象,包含运行时context以及其他信息,如store和stream_writer定义好node函数后,使用add_node方法将这些节点添加到图中。如果在向图中添加节点时未指定名称,系统会为其分配一个与函数名相同的默认名称。
Node是LangGraph中的一个基本处理单元,代表工作流中的一个操作步骤,可以是一个Agent、调用大模型、工具或一个函数(说白了就是绑定一个python函数,具体逻辑可以干任何事情)

python
from functools import partial
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import RetryPolicy
from requests import RequestException, Timeout
# 定义状态
class GraphState(TypedDict):
process_data: dict # 默认更新策略
# 定义一个节点,入参为state
def input_node(state: GraphState) -> GraphState:
print(f"input_node收到的初始值:{state}")
return {"process_data": {"input": "input_value"}}
# 定义带参数的node节点
def process_node(state: dict, param1: int, param2: str) -> dict:
print(state, param1, param2)
return {"process_data": {"process": "process_value"}}
# 重试策略,add_node方法时可选
retry_policy = RetryPolicy(
max_attempts=3, # 最大重试次数
initial_interval=1, # 初始间隔
jitter=True, # 抖动(添加随机性避免重试风暴)
backoff_factor=2, # 退避乘数(每次重试间隔时间的增长倍数)
retry_on=[RequestException, Timeout], # 只重试这些异常
)
stateGraph = StateGraph(GraphState)
# 添加inpu节点
stateGraph.add_node("input", input_node)
# 给process_node节点绑定参数
process_with_params = partial(process_node, param1=100, param2="test")
# 添加带参数的node节点
stateGraph.add_node("process", process_with_params, retry=retry_policy)
# 定义节点之间的执行顺序 edges
# 设置节点间的依赖关系,形成执行流程图
stateGraph.add_edge(START, "input")
stateGraph.add_edge("input", "process")
stateGraph.add_edge("process", END)
# 编译图构建器生成计算图
graph = stateGraph.compile()
# # 打印图的边和节点信息
print(stateGraph.edges)
print(stateGraph.nodes)
# 打印图的可视化结构
print(graph.get_graph().print_ascii())
print()
# 定义一个初始状态字典,包含键值对"x": 5
initial_state = {"process_data": 5}
# 调用graph对象的invoke方法,传入初始状态,执行图计算流程
result = graph.invoke(initial_state)
print(f"最后的结果是:{result}")Node的设计原则:
- 单一职责原则:每个节点应该只负责一项职责,避免功能过于复杂
- 无状态设计:节点本身不应该保存状态,所有数据都通过输入状态传递
- 幂等性:相同的输入应该产生相同的输出,确保可重试性
- 可测试性:节点逻辑应该易于单元测试
特殊的节点 START (开始节点)和 END(结束节点):
- __START__节点:开始节点,确定应该首先调用哪些节点

也可以通过graph.set_entry_point("node_start") 函数设置起始节点,等价于graph.add_edge(START, "node_start")
- __END__节点:终止节点,表示后续没有其他节点可以继续执行了

也可以通过graph.set_finish_point("node_end") 函数设置结束节点,等价于graph.add_edge("node_start", END)
节点缓存Node Caching
LangGraph支持基于节点输入对任务/节点进行缓存。使用缓存的方法如下:
- 编译图(或指定入口点)时指定缓存。
- 为节点指定缓存策略。每个缓存策略支持:
- key_func用于根据节点的输入生成缓存键。
- ttl,即缓存的生存时间(以秒为单位)。如果未指定,缓存将永不过期。
特性:
缓存键与命中:当一个节点开始执行时,系统会使用其配置的 key_func 根据当前节点的输入数据生成一个唯一的键。LangGraph 会检查缓存中是否存在这个键。如果存在(缓存命中),则直接返回之前存储的结果,跳过该节点的实际执行。如果不存在(缓存未命中),则正常执行节点函数,并将结果与缓存键关联后存入缓存。
缓存有效期:ttl 参数能控制缓存的有效期。例如,对于依赖实时数据的天气查询节点,可以设置较短的 ttl(如60秒)。而对于处理静态信息或变化不频繁数据的节点,则可以设置较长的 ttl甚至不设置(None),让缓存永久有效,直到手动清除
python
import time
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from langgraph.cache.memory import InMemoryCache
from langgraph.types import CachePolicy
# 定义状态类,也就是你的业务实体entity
class State(TypedDict):
x: int
result: int
# 创建图
builder = StateGraph(State)
# 定义节点:模拟耗时计算(sleep3秒)
def expensive_node(state: State) -> dict[str, int]:
time.sleep(3)
return {"result": state["x"] * 2}
# builder.add_node("node1", node_default_1)
# 添加节点
builder.add_node(
node="expensive_node",
action=expensive_node,
# 不用传key_fn,底层自动用默认逻辑
cache_policy=CachePolicy(ttl=8),
)
# 设置入口和出口
builder.set_entry_point("expensive_node")
builder.set_finish_point("expensive_node")
# 编译图,指定内存缓存
app = builder.compile(cache=InMemoryCache())
# 第一次执行:耗时3秒(无缓存)
print("第一次执行(无缓存,耗时3秒):")
print(app.invoke({"x": 5}))
# 第二次执行:瞬间返回(利用缓存,8秒内有效)
print("\n1111111111111111111111111111")
print("第二次运行利用缓存并快速返回:")
print(app.invoke({"x": 5}))
# 可选:测试8秒后缓存过期(取消注释查看)
print("\n等待8秒,缓存过期...")
time.sleep(8)
print("8秒后第三次执行(重新计算,耗时3秒):")
print(app.invoke({"x": 5}))错误处理和重试机制
LangGraph还提供了错误处理和重试机制来指定重试次数、重试间隔、重试异常等,用于保证系统的可靠性
为节点添加重试策略,需要在add_node中设置retry_policy参数。retry_policy参数接受一个RetryPolicy命名元组对象。默认情况下,retry_on参数使用default_retry_on函数,该函数会在遇到任何异常时重试
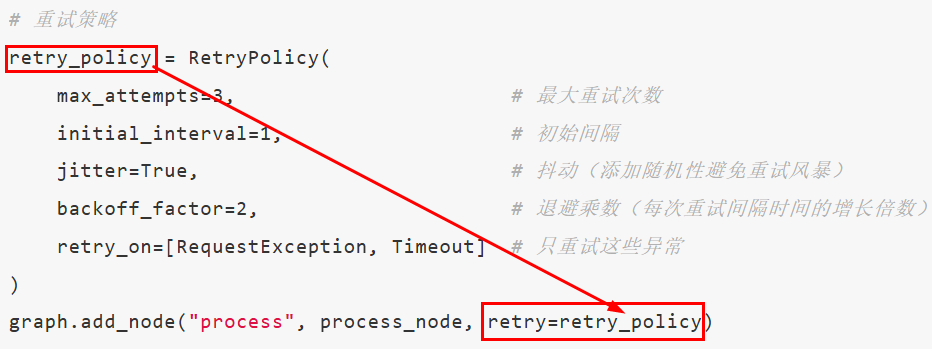
python
"""
LangGraph 节点重试策略演示
默认重试策略:max_attempts=5,对Exception重试、对ValueError/TypeError等不重试,异常过滤列表完全相同;
自定义重试策略:max_attempts=5 + custom_retry_on,仅对包含{模拟API调用失败}的异常重试;throw new RuntimeExp("模拟API调用失败")
不可重试测试:ValueError直接抛错,无重试,max_attempts=3
"""
from typing import Dict, Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import RetryPolicy
# 定义状态类型
class AtguiguState(TypedDict):
result: str
# 全局计数器:记录API尝试次数
attempt_counter = 0
# 工具函数
def build_retry_graph(node_name: str, node_func, retry_policy: RetryPolicy):
builder = StateGraph(AtguiguState)
# 为节点添加重试策略,需要在add_node中设置retry_policy参数。
# retry_policy参数接受一个RetryPolicy命名元组对象。
# 默认情况下,retry_on参数使用default_retry_on函数,该函数会在遇到任何异常时重试
builder.add_node(node_name, node_func, retry_policy=retry_policy)
builder.add_edge(START, node_name)
builder.add_edge(node_name, END)
return builder.compile()
# 模拟不稳定的API调用,使用全局变量跟踪尝试次数
def unstable_api_call(state: AtguiguState) -> Dict[str, Any]:
"""模拟不稳定API:前2次失败,第3次成功(全局计数器记录尝试次数)"""
global attempt_counter
attempt_counter += 1
# 纯文本打印尝试次数
print(f"尝试调用API,这是第 {attempt_counter} 次尝试")
# 模拟失败/成功逻辑:前2次抛异常,第3次返回结果
if attempt_counter < 3:
raise Exception(f"模拟API调用失败abcd (尝试 {attempt_counter})")
return {"result": f"API调用成功,经过 {attempt_counter} 次尝试"}
# 自定义重试条件判断函数
def custom_retry_on(exception: Exception) -> bool:
"""自定义重试规则:只对包含「模拟API调用失败」的异常重试"""
print("########################: " + str(exception))
err_msg = str(exception)
if "模拟API调用失败" in err_msg:
print(f"捕获到可重试异常: {err_msg}")
return True
print(f"捕获到不可重试异常: {err_msg}")
return False
# 模拟抛出 ValueError 的节点
def value_error_call(state: AtguiguState) -> Dict[str, Any]:
"""模拟抛出ValueError:默认重试策略对这类异常不重试"""
print("调用会抛出 ValueError 的节点")
raise ValueError("模拟 ValueError 异常")
# 测试方法1:默认重试策略
def test_default_retry():
global attempt_counter
print("1. 使用默认重试策略:")
print(" 默认策略会对除特定异常外的所有异常进行重试")
print(" 不会重试的异常包括: ValueError, TypeError, ArithmeticError, ImportError,")
print(" LookupError, NameError, SyntaxError, RuntimeError,")
print(
" ReferenceError, StopIteration, StopAsyncIteration, OSError\n"
)
print("测试默认重试策略:")
attempt_counter = 0 # 重置计数器
default_graph = build_retry_graph(
node_name="unstable_api",
node_func=unstable_api_call,
retry_policy=RetryPolicy(max_attempts=5), # 最多5次尝试,足够重试成功
)
try:
result = default_graph.invoke({"result": ""})
print(f"最终结果: {result}\n")
except Exception as e:
print(f"最终失败: {type(e).__name__}: {e}\n")
# 测试方法2:自定义重试策略(输出完全匹配要求)
def test_custom_retry():
global attempt_counter
print("2. 使用自定义重试策略:")
print(" 自定义策略只对特定错误进行重试\n")
print("测试自定义重试策略:")
attempt_counter = 0 # 重置计数器
custom_graph = build_retry_graph(
node_name="custom_retry_api",
node_func=unstable_api_call,
retry_policy=RetryPolicy(max_attempts=5, retry_on=custom_retry_on),
)
try:
result = custom_graph.invoke({"result": ""})
print(f"最终结果: {result}\n")
except Exception as e:
print(f"最终失败: {type(e).__name__}: {e}\n")
# 测试方法3:不可重试异常演示,测试 ValueError(默认策略不会重试)
def test_no_retry_exception():
print("3. 测试不会重试的异常类型:")
print("测试 ValueError(默认策略不会重试):")
no_retry_graph = build_retry_graph(
node_name="value_error_node",
node_func=value_error_call,
retry_policy=RetryPolicy(max_attempts=3),
)
try:
result = no_retry_graph.invoke({"result": ""})
print(f"最终结果: {result}\n")
except Exception as e:
print(f"最终失败: {type(e).__name__}: {e}\n")
# 主演示函数
def run_demo():
print("=== LangGraph 节点重试策略完整演示===")
print("-" * 80 + "\n")
# test_default_retry()
# test_custom_retry()
test_no_retry_exception()
print("-" * 80)
print("=== 演示结束 ===")
# 程序入口
if __name__ == "__main__":
run_demo()API 之 Edge(边)
Edge定义了节点之间的连接和执行顺序,以及不同节点之间是如何通讯的,一个节点可以有多个出边(指向多个节点),多个节点也可以指向同一个节点(Map-Reduce)

Edge定义了节点之间的连接和执行顺序,以及不同节点之间是如何通讯的,一个节点可以有多个出边(指向多个节点),多个节点也可以指向同一个节点(Map-Reduce)
如下是添加边的代码:

关键类型:


python
"""
LangGraph普通边演示
普通边是直接连接两个节点的边,表示无条件地从一个节点跳转到另一个节点。
"""
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
# 定义状态
class AtguiguState(TypedDict):
value: int
step: str
# 定义节点函数
def node_a(state: AtguiguState) -> dict:
"""节点A"""
print("执行节点A")
return {"value": state["value"] + 1, "step": "A执行完毕"}
def node_b(state: AtguiguState) -> dict:
"""节点B"""
print("执行节点B")
return {"value": state["value"] * 2, "step": "B执行完毕"}
def node_c(state: AtguiguState) -> dict:
"""节点C"""
print("执行节点C")
return {"value": state["value"] - 1, "step": "C执行完毕"}
def main():
"""演示普通边"""
print("=== 普通边演示 ===")
# 创建图
builder = StateGraph(AtguiguState)
# 添加节点
builder.add_node("node_a", node_a)
builder.add_node("node_b", node_b)
builder.add_node("node_c", node_c)
# 添加普通边
builder.add_edge(START, "node_a") # 从开始到A
builder.add_edge("node_a", "node_b") # 从A到B
builder.add_edge("node_b", "node_c") # 从B到C
builder.add_edge("node_c", END) # 从C到结束
# 编译图
app = builder.compile()
# 执行图
result = app.invoke({"value": 1})
print(f"执行结果: {result}\n")
# 打印图的边和节点信息
print(builder.edges)
# print(builder.nodes)
# 打印图的ascii可视化结构
print(app.get_graph().print_ascii())
print("=================================")
print()
# 打印图的可视化结构,生成更加美观的Mermaid 代码,通过processon 编辑器查看
print(app.get_graph().draw_mermaid())
if __name__ == "__main__":
main()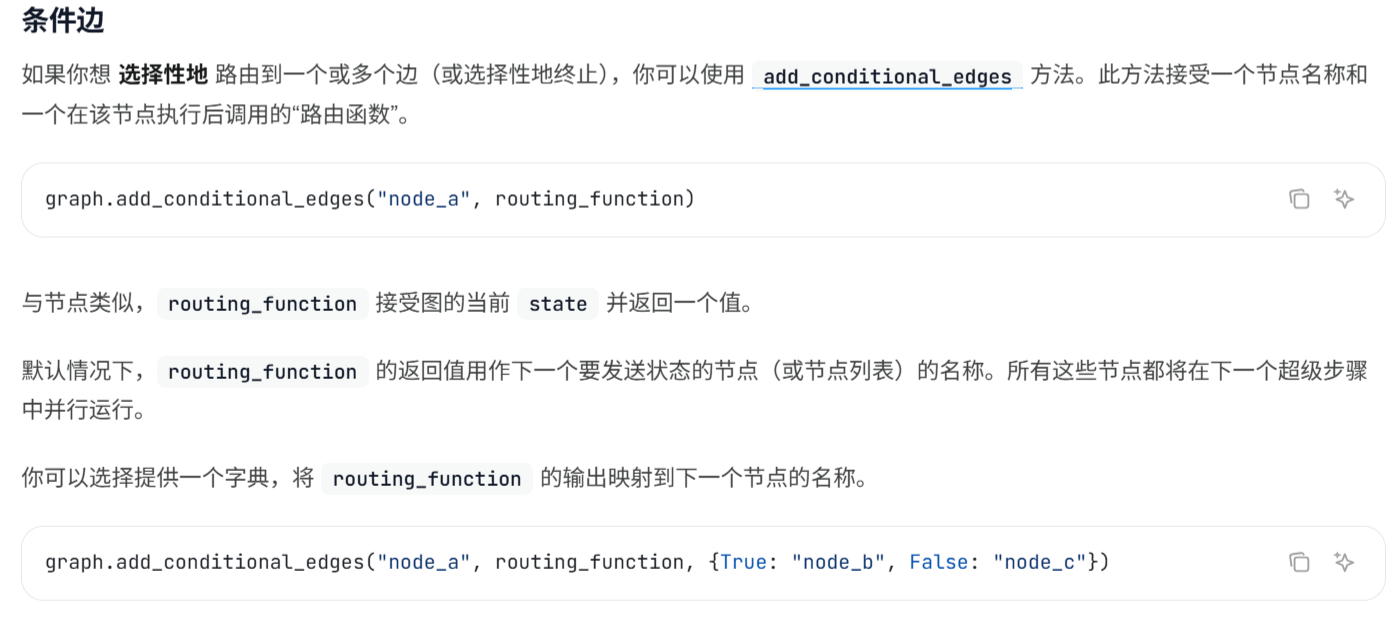
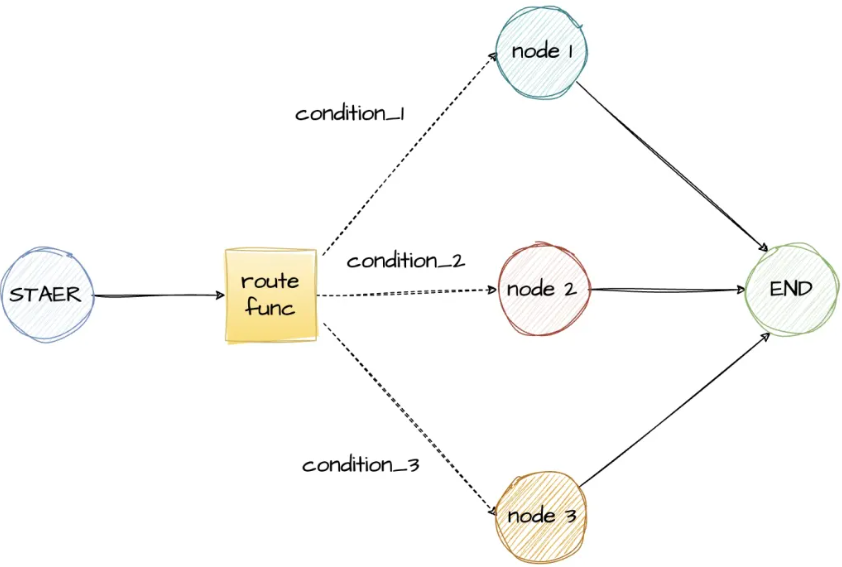
如果你想 选择性地 路由到一个或多个边(或选择性地终止),你可以使用 add_conditional_edges 方法。此方法接受一个节点名称和一个在该节点执行后调用的“路由函数”。
实际应用中,工作流的下一个节点可能并不是固定的,需要根据当前的执行状态去确定需要路由到哪一个节点。条件边可以动态控制执行流程,LangGraph中可以指定路由函数,来选择具体要执行的节点(可以是多个节点)
python
"""
LangGraph 条件边
分支流程控制语句分支路由(Router → Weather / Chat)
使用langgraph构建了一个状态图,根据输入数值的奇偶性执行不同节点。
check_x接收并传递状态,
is_even判断奇偶,
handle_even和handle_odd分别处理偶数和奇数情况,最终输出结果。
"""
from typing import Optional
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from loguru import logger
from pydantic import BaseModel
class MyState(BaseModel):
"""
定义状态模型,用于在图节点之间传递数据
Attributes:
x (int): 输入的整数
result (Optional[str]): 处理结果,可为"even"或"odd"
"""
x: int
result: Optional[str] = None
# 检查输入状态的节点函数
def check_x(state: MyState) -> MyState:
"""
检查输入状态的节点函数
Args:
state (MyState): 包含输入数据的状态对象
Returns:
MyState: 返回原始状态对象,未做修改
"""
logger.info(f"[check_x] Received state: {state}")
return state
# 判断状态中x值是否为偶数的条件函数
def is_even(state: MyState) -> bool:
"""
判断状态中x值是否为偶数的条件函数
Args:
state (MyState): 包含待判断数值的状态对象
Returns:
bool: 如果x是偶数返回True,否则返回False
"""
return state.x % 2 == 0
# 处理偶数情况的节点函数
def handle_even(state: MyState) -> MyState:
"""
处理偶数情况的节点函数
Args:
state (MyState): 包含偶数输入的状态对象
Returns:
MyState: 返回更新后的状态对象,result设置为"even"
"""
logger.info("[handle_even] x 是偶数")
return MyState(x=state.x, result="even")
# 处理奇数情况的节点函数
def handle_odd(state: MyState) -> MyState:
"""
处理奇数情况的节点函数
Args:
state (MyState): 包含奇数输入的状态对象
Returns:
MyState: 返回更新后的状态对象,result设置为"odd"
"""
logger.info("[handle_odd] x 是奇数")
return MyState(x=state.x, result="odd")
builder = StateGraph(MyState)
# 添加节点
builder.add_node("check_x", check_x)
builder.add_node("handle_even", handle_even)
builder.add_node("handle_odd", handle_odd)
# 添加条件边,根据is_even函数的返回值决定流向哪个节点
builder.add_conditional_edges(
"check_x", is_even, {True: "handle_even", False: "handle_odd"}
)
# 添加起始边,从START节点流向check_x节点
builder.add_edge(START, "check_x")
# 添加结束边,从处理节点流向END节点
builder.add_edge("handle_even", END)
builder.add_edge("handle_odd", END)
# 编译图结构
graph = builder.compile()
# 打印图的可视化结构
print(graph.get_graph().print_ascii())
# 测试用例:输入偶数4
# logger.info("输入 x=4(偶数)")
# graph.invoke(MyState(x=4))
# # 测试用例:输入奇数3
logger.info("输入 x=3(奇数)")
graph.invoke(MyState(x=3))python
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, List, Annotated
# 定义状态
class AtguiguState(TypedDict):
x: int
def addition1(state):
"""
执行加法运算的节点函数
参数:
state (dict): 包含输入数据的状态字典,必须包含键"x"
返回:
dict: 返回更新后的状态字典,其中"x"的值增加1
"""
print(f"加法节点addition1收到的初始值:{state}")
return {"x": state["x"] + 1}
def addition2(state):
print(f"加法节点addition2收到的初始值:{state}")
return {"x": state["x"] + 2}
def addition3(state):
print(f"加法节点addition3收到的初始值:{state}")
return {"x": state["x"] + 3}
def route_by_sentiment(state: AtguiguState) -> str:
# 路由逻辑...返回最终的条件
flag = state["x"]
if flag == 1:
return "condition_1"
elif flag == 2:
return "condition_2"
else:
return "condition_3"
graph = StateGraph(AtguiguState)
graph.add_node("node1", addition1)
graph.add_node("node2", addition2)
graph.add_node("node3", addition3)
# 添加路由函数,参数:当前节点,路由函数,路由函数返回的条件与node的映射
graph.add_conditional_edges(
START,
route_by_sentiment,
{"condition_1": "node1", "condition_2": "node2", "condition_3": "node3"},
)
# 所有处理节点都连接到END
graph.add_edge("node1", END)
graph.add_edge("node2", END)
graph.add_edge("node3", END)
app = graph.compile()
# 定义一个初始状态字典,包含键值对"x": 具体数字
initial_state = {"x": 3}
# 调用graph对象的invoke方法,传入初始状态,执行图计算流程
result = app.invoke(initial_state)
print(f"最后的结果是:{result}")
# 打印图的边和节点信息
# print(graph.edges)
# print(graph.nodes)
# 打印图的ascii可视化结构
print(app.get_graph().print_ascii())
print("=================================")
print()
# 打印图的可视化结构,生成更加美观的Mermaid 代码,通过processon 编辑器查看
print(app.get_graph().draw_mermaid())
入口点是图启动时运行的第一个节点。你可以使用 add_edge 方法从虚拟 START 节点到要执行的第一个节点,以指定图的入口
python
"""
LangGraph入口点演示
入口点定义了图开始执行的第一个节点。
"""
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
# 定义状态
class AtguiguState(TypedDict):
value: int
step: str
# 定义节点函数
def node_a(state: AtguiguState) -> dict:
"""节点A"""
print("执行节点A")
print("state[value]:" + str(state["value"]))
print("state[step]:" + str(state["step"]))
return {"value": state["value"] + 1, "step": "A执行完毕"}
def node_b(state: AtguiguState) -> dict:
"""节点B"""
print("执行节点B")
return {"value": state["value"] * 2, "step": "B执行完毕"}
def main():
"""演示入口点"""
print("=== 入口点演示 ===")
# 创建图
builder = StateGraph(AtguiguState)
# 添加节点
builder.add_node("node_a", node_a)
builder.add_node("node_b", node_b)
"""
set_entry_point(node_id) 和 set_finish_point(node_id) 是 LangGraph 为「图对象」提供的配置方法,
核心作用是将你自定义的业务节点,和内置的 START/END 特殊节点做 “自动绑定”,简化图的入口 / 出口边的定义,
本质是语法糖(底层还是帮你执行了 add_edge(START, 入口节点) / add_edge(出口节点, END))
set_entry_point(node_id)
图的实际执行入口是 node_id 这个自定义节点,底层会自动创建一条边 add_edge(START, node_id),
无需你手动写这条边
set_finish_point(node_id)
当流程走到 node_id 这个自定义节点时视为流程结束,底层会自动创建一条边 add_edge(node_id, END),
无需你手动写这条边
"""
builder.set_entry_point("node_a")
builder.add_edge("node_a", "node_b")
builder.set_finish_point("node_b")
# 编译图
graph = builder.compile()
# 执行图
result = graph.invoke({"value": 0, "step": "hello"})
print(f"执行结果: {result}\n")
print()
# 打印图的ascii可视化结构
print(graph.get_graph().print_ascii())
print("=================================")
print()
# 打印图的可视化结构,生成更加美观的Mermaid 代码,通过processon 编辑器查看
print(graph.get_graph().draw_mermaid())
if __name__ == "__main__":
main()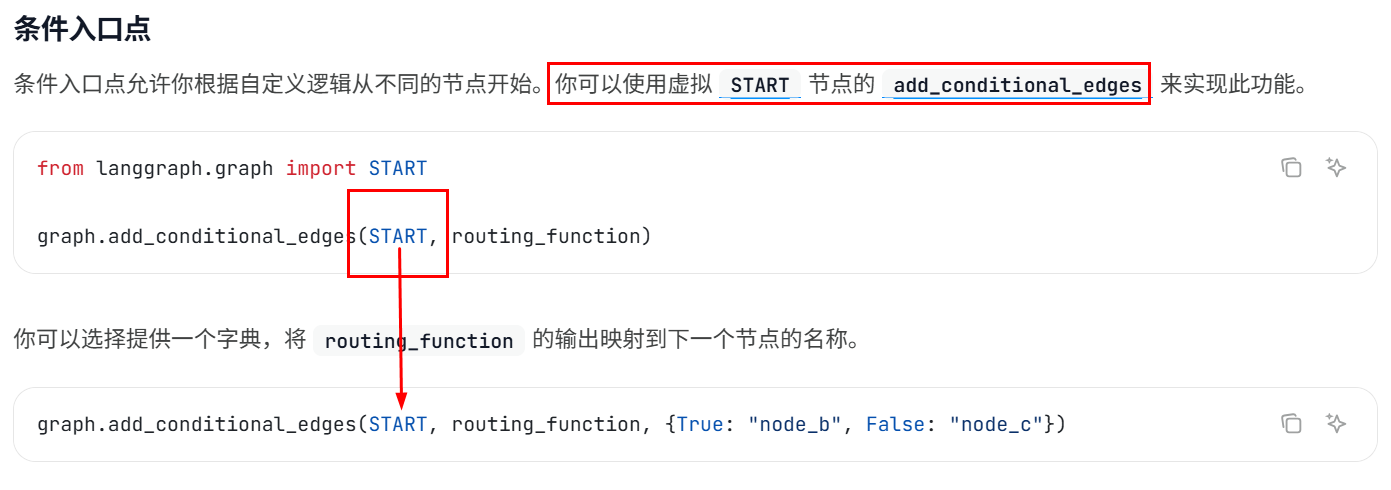
条件入口点允许你根据自定义逻辑从不同的节点开始。你可以使用虚拟 START 节点的 add_conditional_edges 来实现此功能
python
"""
LangGraph中条件入口点的典型应用场景
完整展示了条件入口点的核心概念:根据输入内容动态决定从START节点去往哪个处理节点。
"""
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
# 1. 定义简单的状态
class SimpleState(TypedDict):
user_input: str
response: str
node_visited: str
# 2. 路由函数 - 决定从START去哪
def route_input(state: SimpleState) -> str:
"""根据用户输入决定去哪个节点"""
text = state["user_input"].lower()
if "hello" in text or "hi" in text:
return "greeting" # 返回路由键
elif "bye" in text or "exit" in text:
return "farewell" # 返回路由键
else:
return "question" # 返回路由键
# 3. 各个处理节点
def handle_greeting(state: SimpleState) -> SimpleState:
"""处理问候"""
state["response"] = "你好!很高兴见到你!"
state["node_visited"] = "greeting_node"
return state
def handle_farewell(state: SimpleState) -> SimpleState:
"""处理告别"""
state["response"] = "再见!祝你有个美好的一天!"
state["node_visited"] = "farewell_node"
return state
def handle_question(state: SimpleState) -> SimpleState:
"""处理问题"""
state["response"] = "我听到了你的问题,需要更多帮助吗?"
state["node_visited"] = "question_node"
return state
# 4. 创建图
def create_simple_graph():
"""创建一个简单的图"""
stateGraph = StateGraph(SimpleState)
# 添加节点
stateGraph.add_node("greeting_node", handle_greeting)
stateGraph.add_node("farewell_node", handle_farewell)
stateGraph.add_node("question_node", handle_question)
"""条件入口点
add_conditional_edges(START, route_function, mapping)
START:从图的起点开始
route_function:决定去哪里的函数,返回一个字符串(路由键)
mapping(可选):路由键到节点名的映射
START → route_input()函数 → 返回"greeting" → 映射到"greeting_node" → 执行handle_greeting → END
"""
stateGraph.add_conditional_edges(
START, # 起点
route_input, # 路由函数
# 路由映射(可选):路由函数的返回值 -> 节点名
{
"greeting": "greeting_node", # route_input返回"greeting"时,去greeting_node
"farewell": "farewell_node", # route_input返回"farewell"时,去farewell_node
"question": "question_node", # route_input返回"question"时,去question_node
},
)
# 所有节点都到END
stateGraph.add_edge("greeting_node", END)
stateGraph.add_edge("farewell_node", END)
stateGraph.add_edge("question_node", END)
return stateGraph.compile()
# 5. 使用示例
def run_example():
# 创建图
graph = create_simple_graph()
# 测试不同的输入
test_inputs = ["Hello everyone!", "Goodbye now", "What time is it?"]
for user_input in test_inputs:
print(f"\n输入: {user_input}")
print("-" * 30)
# 创建初始状态
initial_state = SimpleState(user_input=user_input, response="", node_visited="")
# 执行图
result = graph.invoke(initial_state)
print(f"路由决策: {route_input(initial_state)}")
print(f"访问的节点: {result['node_visited']}")
print(f"响应: {result['response']}")
print()
# 打印图的ascii可视化结构
print(graph.get_graph().print_ascii())
print("=================================")
print()
# 打印图的可视化结构,生成更加美观的Mermaid 代码,通过processon 编辑器查看
print(graph.get_graph().draw_mermaid())
# 运行示例
if __name__ == "__main__":
print("简单条件入口点示例")
print("=" * 40)
run_example()API 之 Send/Command/Runtime context
总体概述:Send和Command是两种用于实现高级工作流控制的核心机制,用于支持动态地决定下一步执行哪个节点
Send
Map-Reduce场景
Map-Reduce(映射 - 归约):将一个「大规模的复杂计算任务」拆解成无数个「小任务」并行处理,最后再把小任务的结果汇总得到最终答案。
Map 直译是「映射」,核心行为是:「拆分 + 局部处理」。Reduce 直译是「归约」,核心行为是:「聚合 + 全局计算」
通俗举例:
统计全国所有人的年龄分布,Map 阶段就是「把全国按省份拆分成 34 个分片,每个省份独立统计本省的年龄→人数(KV 对:20 岁→100 万,21 岁→98 万)」。Reduce 阶段就是「把 34 个省份的 KV 对按年龄分组,比如所有省份的「20 岁」Value 求和,得到全国 20 岁总人数;所有省份的「21 岁」Value 求和,得到全国 21 岁总人数」,最终汇总成全国年龄分布表。
核心思想:
拆分任务 →并行执行 → 统一汇总结果
Send就是动态创建多个执行分支,实现并行处理,每个Send对象都指定了一个执行目标节点和传递给该节点的参数,LangGraph会并行执行所有的这些任务,常用在Map-Reduce的场景,并行执行多个子节点并最终汇总到一个总节点。
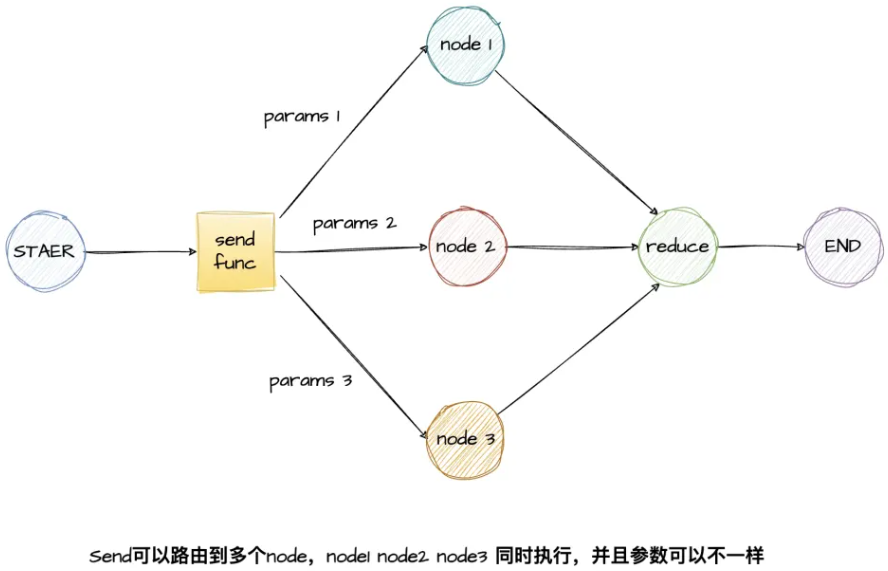
为了支持这种设计模式,LangGraph支持从条件边返回 Send 对象
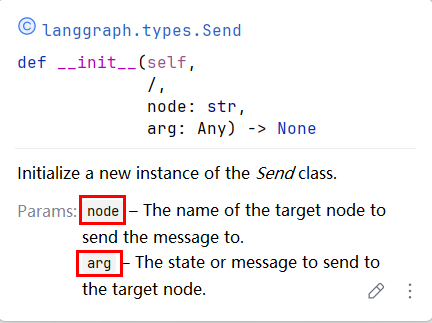
Send 接受两个参数:第一个是节点的名称;第二个是要传递给该节点的状态
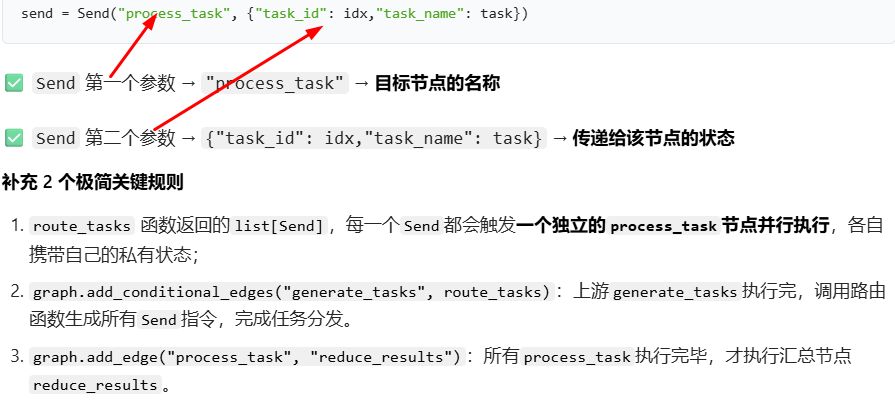
python
"""
SendDemo.py
LangGraph Map-Reduce 模式演示
通过使用 Send 对象,LangGraph 提供了一种优雅的方式来实现这种动态图结构,
使得我们可以根据运行时状态来决定执行路径。
解释:
(1)首先执行 generate_subjects主题列表节点,生成主题列表:['猫', '狗', '程序员']
(2)然后通过条件边函数 map_subjects_to_jokes 为每个主题创建一个 Send 对象
(3)make_joke 节点被并行执行3次,每次处理一个主题
(4)最终将所有生成的笑话合并到一个列表中
这种模式非常适合处理动态数量的任务
"""
from typing import Annotated, List, Sequence
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
# 定义状态
class AtguiguState(TypedDict):
subjects: List[str]
jokes: Annotated[List[str], lambda x, y: x + y] # 使用列表合并的方式
# 第一个节点:生成需要处理的主题列表
def generate_subjects(state: AtguiguState) -> dict:
"""生成需要处理的主题列表"""
print("执行节点(第一个节点:生成需要处理的主题列表): generate_subjects")
subjects = ["猫", "狗", "程序员"]
print(f"生成主题列表: {subjects}")
return {"subjects": subjects}
# Map节点:为每个主题生成笑话
def make_joke(state: AtguiguState) -> dict:
"""为单个主题生成笑话"""
subject = state.get("subject", "未知")
print(f"执行节点: make_joke,处理主题: {subject}")
# 根据主题生成相应笑话
jokes_map = {
"猫": "为什么猫不喜欢在线购物?因为它们更喜欢实体店!",
"狗": "为什么狗不喜欢计算机?因为它们害怕被鼠标咬!",
"程序员": "为什么程序员喜欢洗衣服?因为他们在寻找bugs!",
"未知": "这是一个关于未知主题的神秘笑话。",
}
joke = jokes_map.get(subject, f"这是一个关于{subject}的即兴笑话。")
print(f"生成笑话: {joke}")
return {"jokes": [joke]}
# 条件边函数:根据主题列表生成Send对象列表
def map_subjects_to_jokes(state: AtguiguState) -> List[Send]:
"""将主题列表映射到joke生成任务"""
print("执行条件边函数: map_subjects_to_jokes")
subjects = state["subjects"]
print(f"映射主题到joke任务: {subjects}")
# 为每个主题创建一个Send对象,指向make_joke节点
# 每个Send对象包含节点名称和传递给该节点的状态
send_list = [Send("make_joke", {"subject": subject}) for subject in subjects]
print(f"生成Send对象列表: {send_list}")
return send_list
def main():
"""演示Map-Reduce模式"""
print("=== Map-Reduce 模式演示 ===\n")
# 创建图
builder = StateGraph(AtguiguState)
# 添加节点
builder.add_node("generate_subjects", generate_subjects)
builder.add_node("make_joke", make_joke)
# 添加边
builder.add_edge(START, "generate_subjects")
# 添加条件边,使用Send对象实现map-reduce
builder.add_conditional_edges(
"generate_subjects", # 源节点
map_subjects_to_jokes, # 路由函数,返回Send对象列表
)
# 从make_joke到结束
builder.add_edge("make_joke", END)
# 编译图
graph = builder.compile()
print(graph.get_graph().print_ascii())
# 执行图
initial_state = {"subjects": [], "jokes": []}
print("初始状态:", initial_state)
print("\n开始执行图...")
result = graph.invoke(initial_state)
print(f"\n最终结果: {result}")
print("\n=== 演示完成 ===")
if __name__ == "__main__":
main()Command
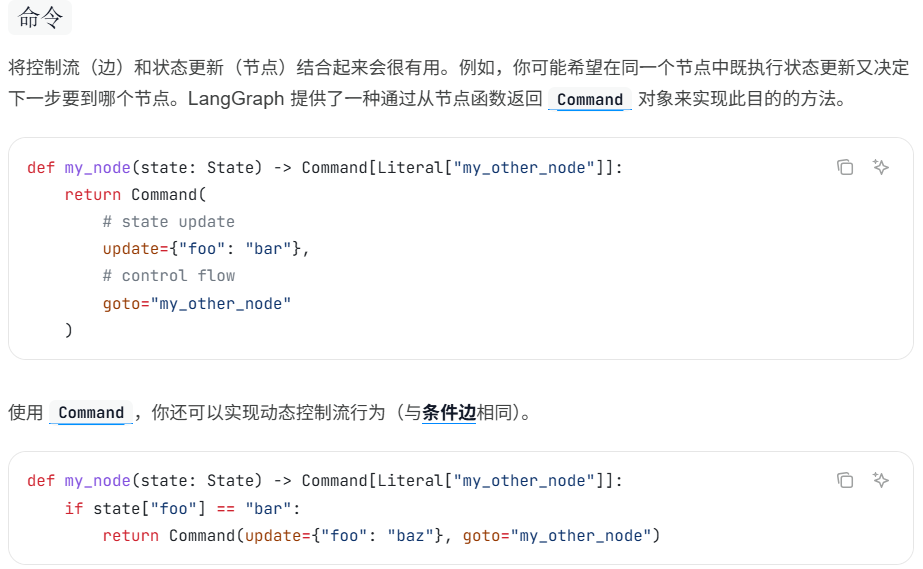
在同一个节点中既执行状态更新,又决定下一步前往哪个节点,LangGraph 提供了一种实现方式,即从节点函数返回一个 Command 对象
command只能路由到一个节点,并且更新当前的State。走条新路,状态更新。
python
"""
CommandDemo.py | LangGraph 1.0.6 正式版
Command 基础演示:状态更新+流程控制+动态路由
"""
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command
# 全局常量:统一递归限制,便于维护
RECURSION_LIMIT = 50
# 定义状态
class AgentState(TypedDict):
messages: Annotated[list, lambda x, y: x + y] # 自动合并消息
current_agent: str
task_completed: bool
# 决策代理(核心路由节点)
def decision_agent(state: AgentState) -> Command[AgentState]:
"""根据消息内容路由代理,任务完成则直接终止"""
print("执行节点: decision_agent")
# 优先终止流程(核心防循环逻辑)
if state["task_completed"]:
print("✅ 检测到任务已完成,直接终止流程")
return Command(
update={"messages": [("system", "所有任务处理完成,流程正常结束")]},
goto=END,
)
# 提取消息文本(兼容空消息)
last_message = state["messages"][-1] if state["messages"] else ("", "")
last_msg_content = last_message[1]
print(f"最新消息文本: {last_msg_content}")
# 动态路由
if "数学" in last_msg_content:
print("✅ 检测到数学任务,路由到数学代理")
return Command(
update={
"messages": [("system", "路由到数学代理")],
"current_agent": "math_agent",
},
goto="math_agent",
)
elif "翻译" in last_msg_content:
print("✅ 检测到翻译任务,路由到翻译代理")
return Command(
update={
"messages": [("system", "路由到翻译代理")],
"current_agent": "translation_agent",
},
goto="translation_agent",
)
else:
print("❌ 未识别任务类型,标记任务完成并终止")
return Command(
update={"messages": [("system", "任务完成")], "task_completed": True},
goto=END,
)
# 数学代理(业务节点)
def math_agent(state: AgentState) -> Command[AgentState]:
"""处理数学计算任务,完成后返回决策代理"""
print("执行节点: math_agent")
result = "2 + 2 = 4"
print(f"计算结果: {result}")
return Command(
update={
"messages": [("assistant", f"数学计算结果: {result}")],
"current_agent": "decision_agent",
"task_completed": True,
},
goto="decision_agent",
)
# 翻译代理(业务节点)
def translation_agent(state: AgentState) -> Command[AgentState]:
"""处理中英翻译任务,完成后返回决策代理"""
print("执行节点: translation_agent")
translation = "Hello -> 你好"
print(f"翻译结果: {translation}")
return Command(
update={
"messages": [("assistant", f"翻译结果: {translation}")],
"current_agent": "decision_agent",
"task_completed": True,
},
goto="decision_agent",
)
def main():
"""演示Command基础用法:状态更新+动态路由+流程终止"""
print("=== Command 基础演示(LangGraph 1.0.6)===\n")
# 1. 构建状态图
builder = StateGraph(AgentState)
builder.add_node("decision_agent", decision_agent)
builder.add_node("math_agent", math_agent)
builder.add_node("translation_agent", translation_agent)
# 2. 定义边(完整节点关系)
builder.add_edge(START, "decision_agent")
builder.add_edge("math_agent", "decision_agent")
builder.add_edge("translation_agent", "decision_agent")
builder.add_edge("decision_agent", END)
# 3. 编译图
graph = builder.compile()
# 测试1:数学任务
print("【测试1: 数学任务】")
initial_state = {
"messages": [("user", "我需要计算数学题")],
"current_agent": "user",
"task_completed": False,
}
print("初始状态:", initial_state)
result = graph.invoke(initial_state, recursion_limit=RECURSION_LIMIT)
print(
"最终状态(简化):", {k: v for k, v in result.items() if k != "messages"}
) # 简化输出
print("\n" + "-" * 50 + "\n")
# 测试2:翻译任务
print("【测试2: 翻译任务】")
initial_state = {
"messages": [("user", "我需要翻译文本")],
"current_agent": "user",
"task_completed": False,
}
print("初始状态:", initial_state)
result = graph.invoke(initial_state, recursion_limit=RECURSION_LIMIT)
print("最终状态(简化):", {k: v for k, v in result.items() if k != "messages"})
print("\n" + "-" * 50 + "\n")
# 测试3:未识别任务
print("【测试3: 未识别任务类型】")
initial_state = {
"messages": [("user", "你好")],
"current_agent": "user",
"task_completed": False,
}
print("初始状态:", initial_state)
result = graph.invoke(initial_state, recursion_limit=RECURSION_LIMIT)
print("最终状态(简化):", {k: v for k, v in result.items() if k != "messages"})
# 新增:可视化图结构(教学演示必备)
print("\n=== 图结构可视化 ===")
print(graph.get_graph().draw_mermaid())
if __name__ == "__main__":
main()题外话:
Command vs Conditional Edges条件边
Command与条件边的区别是:条件边只会路由下一个node节点,而Command不仅路由下一个node节点,还支持状态更新,如果需要同时更新状态和路由到不同的节点时,则使用 Command。
Runtime context运行时上下文
创建图时,可以指定运行时上下文,将上下文信息(不属于图状态的信息)传递给节点,以便节点中使用,例如模型名称或数据库连接等。
使用 context_schema 的优势:
- 分离关注点:将运行时配置与图状态分离,保持状态的纯净性
- 类型安全:通过定义数据类,提供类型检查和 IDE 自动补全支持
- 易于管理:统一管理运行时依赖,如数据库连接、API密钥等
Runtime context运行时上下文 类似微服务的YML文件,配置和代码分离,信息从配置文件读取
使用方式:
- Context Schema(上下文结构):使用 @dataclass 定义了一个 ContextSchema类,定义的内容不属于图的状态,但在运行时需要被节点访问
- 节点函数定义:节点函数接收两个参数:state(图的状态)和 runtime(运行时上下文);通过 runtime.context 访问上下文信息,如 runtime.context.model_name
- 图的创建和执行:创建 StateGraph 时传入 context_schema=ContextSchema 参数;调用 graph.invoke() 时通过 context 参数传递上下文数据
python
"""
RuntimeContextDemo.py
LangGraph Context Schema 演示
演示如何在 LangGraph 1.0 中使用 context_schema 向节点传递不属于图表状态的信息。
这在传递模型名称、数据库连接等依赖项时非常有用。
"""
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.runtime import Runtime
from langchain_core.messages import AIMessage, HumanMessage
from dataclasses import dataclass
# 定义状态结构
class AgentState(TypedDict):
messages: Annotated[list, lambda x, y: x + y]
response: str
# 定义上下文结构
@dataclass
class ContextSchema:
model_name: str
db_connection: str
api_key: str
# 节点函数:处理用户消息
def process_message(state: AgentState, runtime: Runtime[ContextSchema]) -> dict:
"""处理用户消息的节点,使用context中的信息"""
print("执行节点: process_message")
# 获取最新的用户消息
last_message = state["messages"][-1].content if state["messages"] else ""
print(f"用户消息: {last_message}")
print("=========以下是从RuntimeContext中获得信息=========")
# 使用runtime.context中的信息
model_name = runtime.context.model_name
db_connection = runtime.context.db_connection
api_key = runtime.context.api_key
print(f"使用的模型: {model_name}")
print(f"数据库连接: {db_connection}")
print(f"API密钥前缀: {api_key[:5]}***") # 只显示前5位,隐藏其余部分
# 模拟使用这些信息处理请求
response = f"使用 {model_name} 处理了您的请求,已连接到 {db_connection}"
return {"messages": [AIMessage(content=response)], "response": response}
# 节点函数:生成最终响应
def generate_response(state: AgentState, runtime: Runtime[ContextSchema]) -> dict:
"""生成最终响应的节点"""
print("执行节点: generate_response")
# 使用runtime.context中的信息
model_name = runtime.context.model_name
print(f"使用模型 {model_name} 生成最终响应")
# 获取之前的结果
previous_response = state["response"]
# 生成更详细的响应
final_response = f"{previous_response}\n\n这是使用 {model_name} 生成的完整响应。"
return {"messages": [AIMessage(content=final_response)], "response": final_response}
def main():
"""演示 context_schema 的使用"""
print("=== Context Schema 演示 ===\n")
# 定义上下文
context = ContextSchema(
model_name="gpt-4-turbo",
db_connection="postgresql://user:pass@localhost:5432/orders_db",
api_key="sk-abcdefghijklmnopqrstuvwxyz123456",
)
# 创建图,指定state_schema和context_schema
builder = StateGraph(AgentState, context_schema=ContextSchema)
# 添加节点
builder.add_node("process_message", process_message)
builder.add_node("generate_response", generate_response)
# 添加边
builder.add_edge(START, "process_message")
builder.add_edge("process_message", "generate_response")
builder.add_edge("generate_response", END)
# 编译图
graph = builder.compile()
# 定义初始状态
initial_state = {
"messages": [HumanMessage(content="请帮我查询最新的订单信息")],
"response": "",
}
print("初始状态:", initial_state)
print()
print(
"上下文信息:\n",
{
"model_name": context.model_name,
"db_connection": context.db_connection,
"api_key": f"{context.api_key[:5]}***",
},
)
print("\n" + "-" * 50 + "\n")
# 执行图,通过context参数传递上下文
result = graph.invoke(initial_state, context=context)
print("\n" + "=" * 50)
print("最终状态:", result)
print("\n最终响应:")
print(result["response"])
if __name__ == "__main__":
main()